An Introduction to the Goodreads APIs
JSON and XML parsing:
How the Data is Passed
JSON
JSON ("JavaScript Object Notation") is a readable text/string adaptation of JavaScript that uses object/attribute and value pairs. While it comes from JavaScript, it can be generated and parsed in many other programming languages as needed. It is widely used with APIs (arguably more now than XML) but Goodreads uses JSON, XML and sometimes the option to choose between the formats to get back from your API requests. To see what these response formats might look like, compare the following:
{"books":[{"id":265130,"isbn":"0679600841","isbn13":"9780679600848","ratings_count":173,"reviews_count":340,"text_reviews_count":23,"work_ratings_count":156294,"work_reviews_count":406706,"work_text_reviews_count":6703,"average_rating":"4.10"}]}
or:
{
"books": [{
"id": 265130,
"isbn": "0679600841",
"isbn13": "9780679600848",
"ratings_count": 173,
"reviews_count": 340,
"text_reviews_count": 23,
"work_ratings_count": 156294,
"work_reviews_count": 406706,
"work_text_reviews_count": 6703,
"average_rating": "4.10"
}]
}
You can get more information on JSON at:
XML
XML, or "eXtensible Markup Language" looks at lot like HTML to the eye. It contains data demarcated by tags, and was designed to be generally usable, such as for documentation. It is widely used for data structures such as those passed via an API like Goodreads, and also in a number of office applications such as MS Office, Open Office, etc.
Goodreads generally uses XML for exchanges of larger quantities of text, while JSON is preferable for smaller strings or collections of text.
Here is an example of raw XML data from the Microsoft XML Core Services (MSXML) SDK:

For more information on XML, check out the resource below.
Parsing JSON
Here we mean parsing as breaking down into logical, syntactic components, so it can be more easily used. In your JavaScript, the JSON and XML is parsed differently. As you might expect, JavaScript can easily handle JSON, with a built in parsing function:
//where "text" is valid JSON text var someObj = JSON.parse(text);
You can also use JavaScript to easily convert into JSON, with:
//the reverse, turning a JS object to a JSON text var text = JSON.stringify(someObj);
We can combine this with the GET syntax we've already been using in JavaScript to create something like:
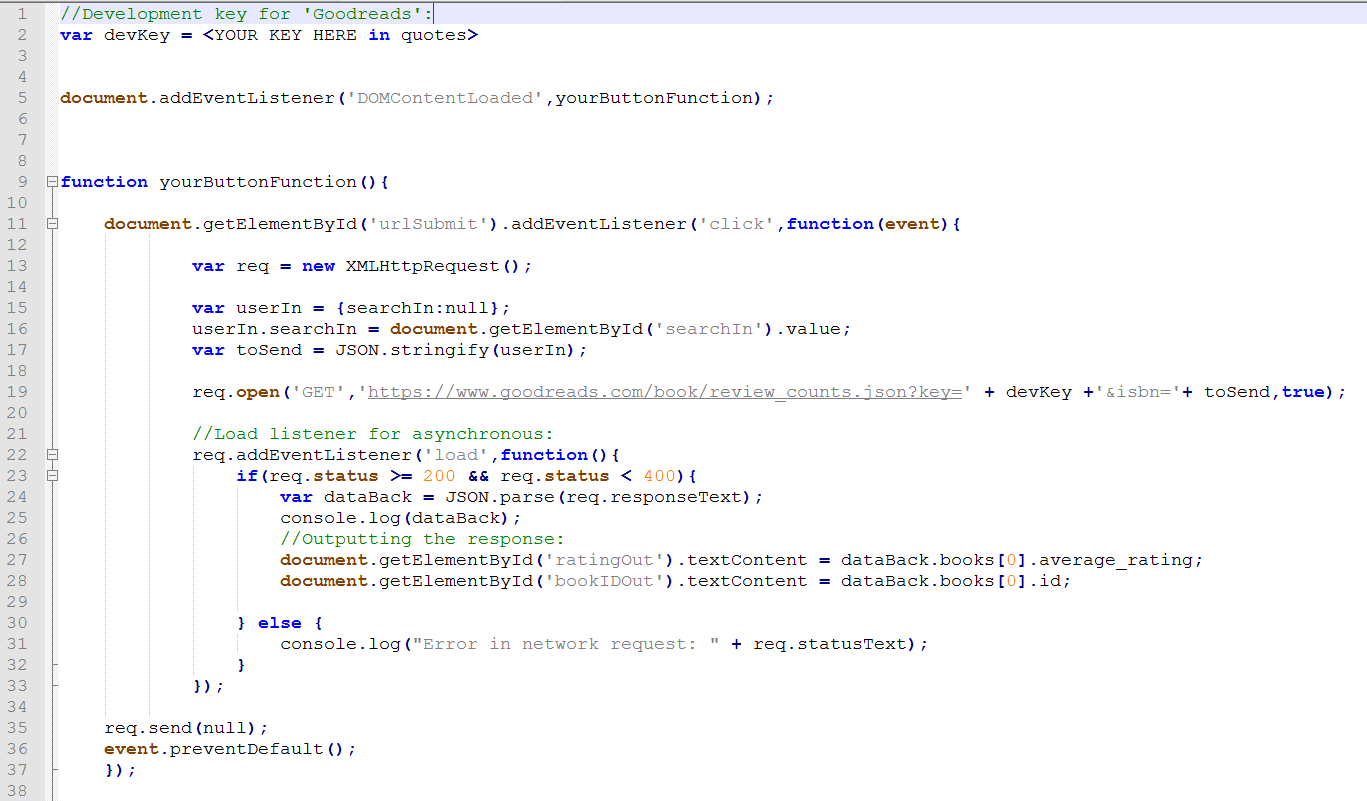
In this example, we've taken a GET as before, but added several new elements. Instead of pre-defining the
ISBN as a variable, we're getting our search term as text entry from the user on our HTML page (far more useful!)
under the ID name 'searchIn'. We "stringify" this (though it is already text) as 'toSend' and concatenate it with
our GET request URL ('https://www.goodreads.com/book/review_counts') and the format option (here '.json'), the key
('?key=' + devKey) and our string search term ('&isbn=' + toSend).
Parsing XML
While XML is already in a tag-delimited format, we will often need to traverse it manually in order to select or display what we are looking for. While there is nothing quite so easily built-in as JSON.parse() or JSON.stringify, there are numerous means of traversing XML data in JavaScript and JQuery. (Note there are far easier means using JQuery, but for this tutorial we will continue with JavaScript.)
Let's look at one means of traversing XML data we have gotten back from our API query (we'll look at another later):
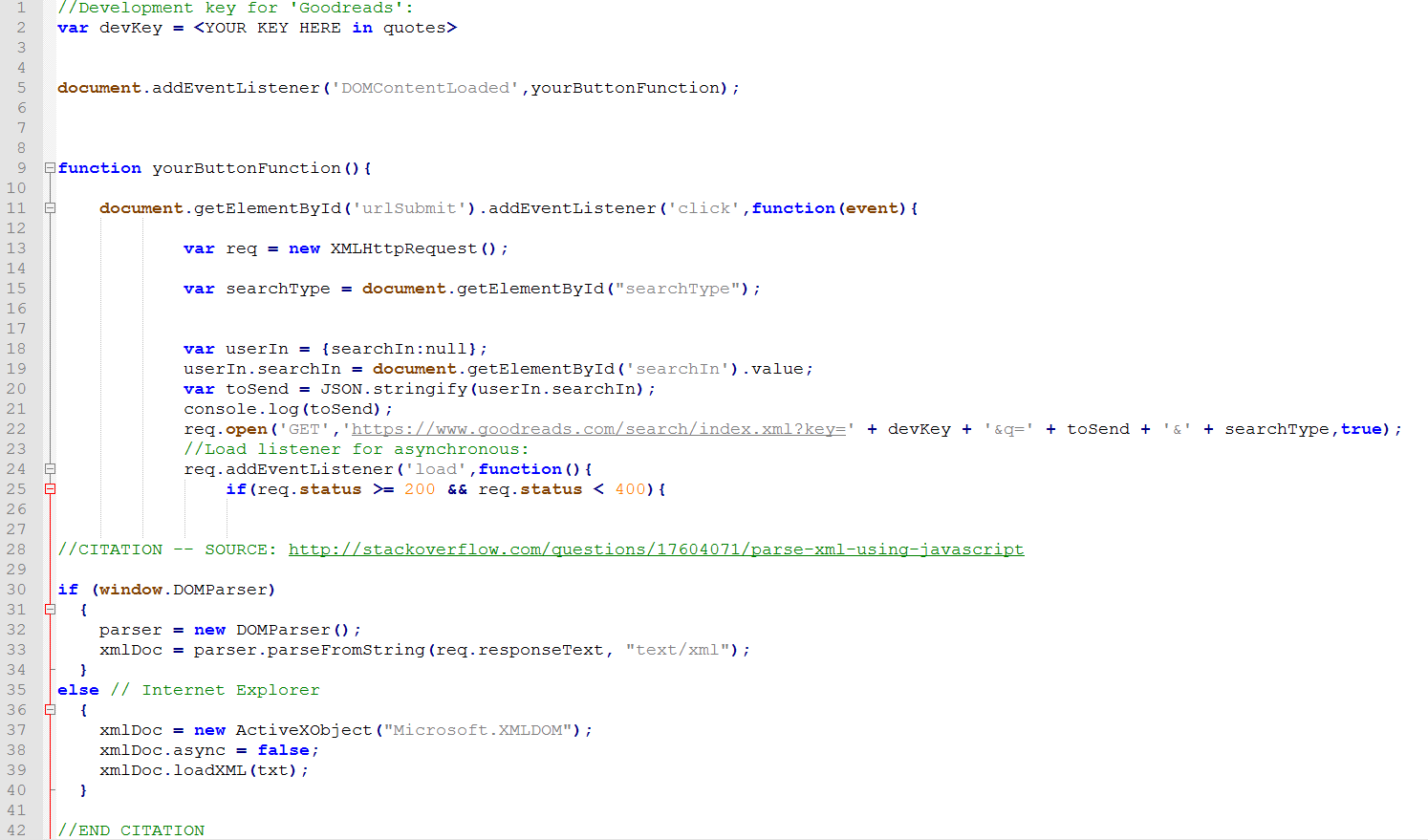
As you can see, we're continuing to build on our query, now taking XML search data back. Little is changed, as we're getting a full search back now, like the search engine we will be finishing -- and in order to display the data, we need to parse it from the XML. As you can see from the comments, this specific code solution comes from stackoverflow. Click the link below to read the original question and answer regarding this process, which grabs the XML and stores it for extraction:
Check out W3 Schools for more on parsing XML content with JavaScript
Visit stackoverflow for the source of this XML parsing script
Now on to doing more from our GETs!